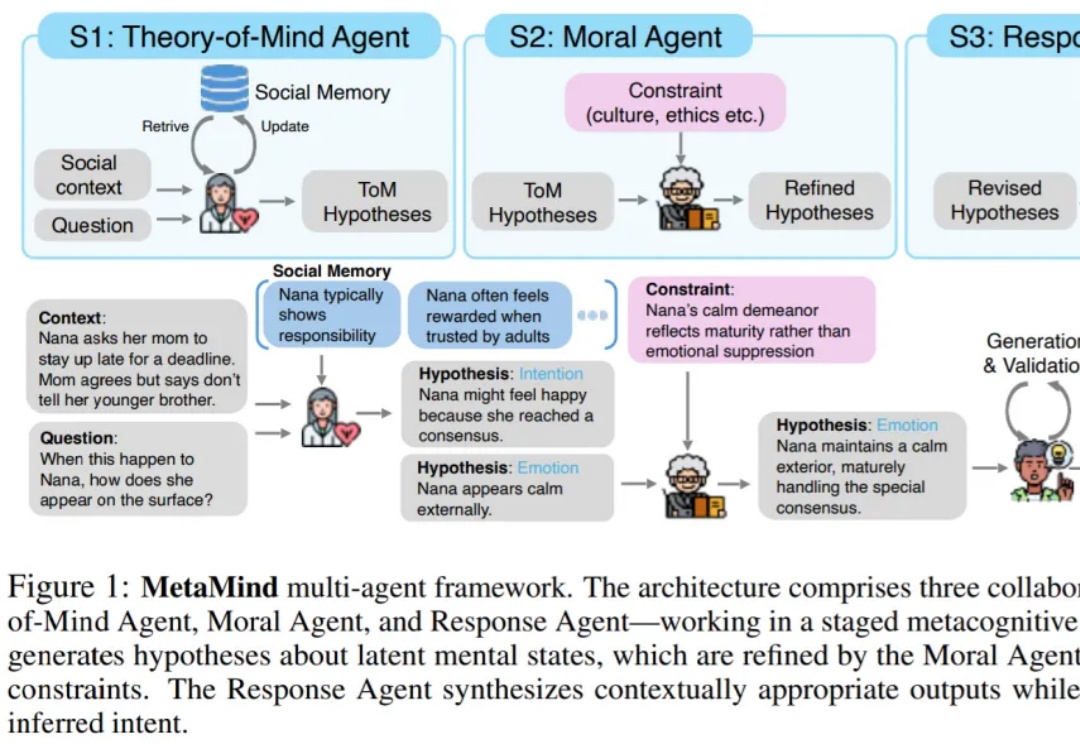
AI终于学会「读懂人心」,带飞DeepSeek R1,OpenAI o3等模型
AI终于学会「读懂人心」,带飞DeepSeek R1,OpenAI o3等模型“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice
来自主题: AI技术研报
9132 点击 2025-11-21 09:16
 搜索
搜索
“What is meant often goes far beyond what is said, and that is what makes conversation possible.” ——H. P. Grice

近日,微博正式发布首个自研开源大模型VibeThinker,这个仅拥有15亿参数的“轻量级选手”,在国际顶级数学竞赛基准测试上击败了参数量是其数百倍的、高达6710亿的DeepSeek R1模型。

小米的最新大模型科研成果,对外曝光了。就在最近,小米AI团队携手北京大学联合发布了一篇聚焦MoE与强化学习的论文。而其中,因为更早之前在DeepSeek R1爆火前转会小米的罗福莉,也赫然在列,还是通讯作者。
来自加拿大蒙特利尔三星先进技术研究所(SAIT)的高级 AI 研究员 Alexia Jolicoeur-Martineau 介绍了微型递归模型(TRM)。这个 TRM 有多离谱呢?一个仅包含 700 万个参数(比 HRM 还要小 4 倍)的网络,在某些最困难的推理基准测试中,
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。

没等到Deepseek R2,DeepSeek悄悄更新了V 3.1。官方群放出的消息就提了一点,上下文长度拓展至128K。128K也是GPT-4o这一代模型的处理Token的长度。因此一开始,鲸哥以为从V3升级到V 3.1,以为是不大的升级,鲸哥体验下来还有惊喜。
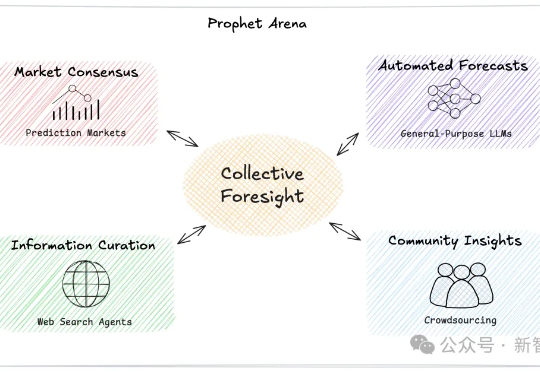
AI能像科幻电影中的先知一样预测未来吗?一个名为「Prophet Arena」的全新基准测试,正通过预测真实世界事件来评估AI的「预言」能力。

GPT-5刚发布没多久,DeepSeek-R2就快来了,好热闹的8月份! DeepSeek预计将于8月发布其新一代旗舰模型DeepSeek-R2。
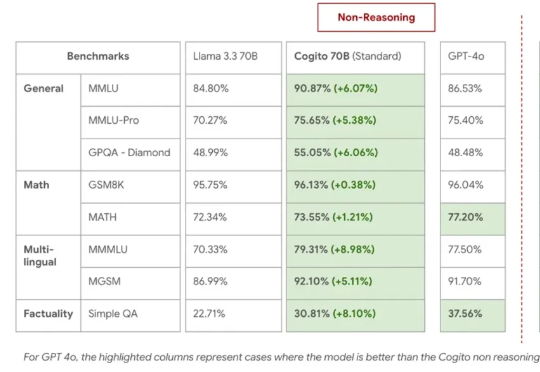
Deep Cogito,一家鲜为人知的 AI 初创公司,总部位于旧金山,由前谷歌员工创立,如今开源的四款混合推理模型,受到大家广泛关注。